Gennaio, 2020
Il modello matematico che stima il valore commerciale di un immobile
(imparando dai propri errori)
Claudio Peroni
Artificial Intelligence, Machine Learning, Big Data, Neural Networks, Deep Learning…
Questi sono solo alcuni dei nomi che, da qualche tempo a questa parte, non possono non comparire in ogni progetto definito innovativo. Perché? Ma soprattutto, cosa vogliono dire?
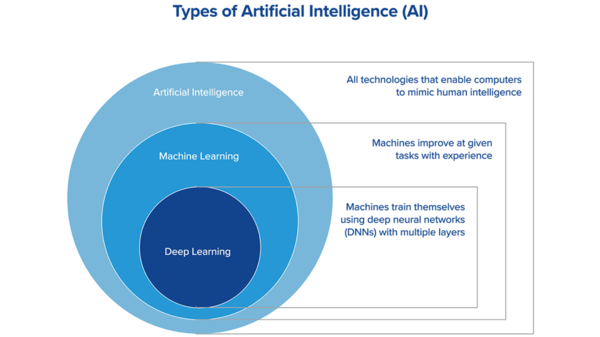
Quella che chiamiamo Intelligenza Artificiale (o, forse più accuratamente, Intelligenza Alternativa) altro non è che un software in grado di comportarsi in maniera "intelligente" rispetto ad uno o più compiti.
Secondo questa definizione, un qualunque algoritmo formato da un numero finito di step può essere definito un’intelligenza artificiale.
Un esempio di questo può essere il giocatore perfetto di tris (tic tac toe). Un software può essere programmato per vincere (o non perdere) mai a questo semplice gioco in una decina di precise istruzioni. L’intelligenza di questo programma è ovviamente limitata ad uno specifico gioco, ma le mosse che compierà non saranno mai meno intelligenti di quelle del più esperto giocatore umano.
Una caratteristica fondamentale di un’intelligenza di questo tipo che cozza con la nostra idea di "intelligenza" è l’incapacità di apprendere autonomamente, e di imparare e migliorare dai propri errori.
Le intelligenze artificiali che superano questa importante limitazione sono quelle basate sul Machine Learning (o Apprendimento Automatico), che stanno vedendo una rapida diffusione negli ultimi anni.
Il Machine Learning è un insieme di tecniche basate sulla statistica che permettono ad un software di imparare le strategie ottimali per portare a termine un certo compito attraverso l’analisi di dati. In parole povere, permettono alla macchina di imparare da un set di esempi a disposizione, da cui il nome.
Gli algoritmi di Machine Learning si basano su un set di dati disponibili (training set) ed utilizzano le correlazioni trovate autonomamente nei dati per agire su un set di dati di interesse (per esempio, per effettuare previsioni sul futuro).
Un esempio potrebbe essere una macchina che, invece di essere specificamente programmata per compiere sempre la mossa ottimale a tris, impari a giocare senza conoscere esplicitamente la strategia ottimale dopo aver osservato qualche centinaio di partite tra giocatori umani.
Ci sono tre principali categorie di Apprendimento Automatico: Supervisionato, Non Supervisionato e basato sul rinforzo.
Il Machine Learning supervisionato si occupa di trovare una risposta a domande quantitative precise, come ad esempio “che temperatura farà domani a mezzogiorno?”, oppure “questa è la foto di un gatto o di un cane?”. In particolare il primo esempio rientra nella sottocategoria di regressione, che offre un output numerico, ed il secondo nella sottocategoria di classificazione, che offre in output la classe di appartenenza dell’osservazione in input.
Gli algoritmi supervisionati vengono addestrati su un training set in cui è presente la variabile “target”, ovvero l’obiettivo che l’algoritmo deve imparare a predire.
Il Machine Learning non supervisionato comprende le tecniche utilizzate per permettere ad una macchina di analizzare autonomamente un set di dati ed effettuare qualche operazione autonoma, come ad esempio una divisione in categorie. Un classico esempio è quello dei gusti e delle preferenze, in cui viene lasciato ad una macchina il compito di analizzare i dati delle preferenze degli utenti di una piattaforma per dividerli autonomamente in alcune categorie ed effettuare raccomandazioni in base ad esse.
La differenza con un algoritmo di classificazione supervisionato è che il target non viene fornito a priori, ma viene stabilito in autonomia (nel dell’esempio di prima, con foto contenenti gatti e cani, non verrà comunicato alla macchina quali sono gatti e quali sono cani, ma le verrà chiesto di dividere le foto in due, e la divisione potrebbe risultare diversa).
Il Reinforcement Learning è utilizzato per permettere ad un algoritmo di imparare con un approccio trial and error. All’algoritmo vengono soltanto dati un set di regole ed qualche metrica per imparare a valutare sé stesso. L’apprendimento funziona per iterazioni, e ad ogni iterazione la macchina riceve un feedback positivo o negativo a seconda di quanto è riuscita ad avvicinarsi all’obiettivo.
Un esempio potrebbe essere una macchina che impara a giocare a scacchi. Anche senza nessuna cognizione sulle strategie del gioco, la macchina presto imparerebbe a proteggere il proprio Re a furia di feedback negativo, e imparerebbe ad attaccare il Re avversario a furia di feedback positivo.
Tra le varie tecniche di Machine Learning che vengono utilizzate, le più recenti (o meglio, le più promettenti di recente) sono quelle basate su Reti Neurali.
Le reti neurali sono software che simulano un complesso sistema formato da particelle elementari, i neuroni, che emettono certi output a partire dagli input che ricevono. Intuitivamente, il design di queste reti è ispirato allo studio del cervello umano e animale. I neuroni possono essere organizzati in più strati collegati tra loro e in configurazioni dotate di feedback. In particolare, quando il sistema diventa particolarmente convoluto, con molti strati, si inizia a parlare di Deep Neural Networks (Reti Neurali Profonde) o, comunemente, di Deep Learning.
Questa tipologia di modelli di Machine Learning offre indubbi vantaggi nella capacità di apprendere da data set di dimensioni considerevoli con una struttura complessa (Big Data), ma pecca di interpretabilità. Ad esempio, da un algoritmo di regressione lineare è possibile non solo trarre delle previsioni, ma è anche possibile interpretare l’apprendimento del modello e di conseguenza imparare qualcosa sulla struttura dei dati che ha ricostruito la macchina. Con una rete neurale, è fondamentalmente impossibile interpretare la struttura dei dati che è stata appresa, nonostante le performance predittive siano solitamente migliori. In molte applicazioni questo è un difficile trade-off.
I modelli e gli algoritmi di Machine Learning possono essere applicati sostanzialmente in qualunque ambito vi siano dei dati disponibili. Le tecniche da applicare variano comunque a seconda dei casi. Spesso è preferibile scegliere un algoritmo più semplice a parità di performance, e a seconda delle circostanze alcune alternative non sono proprio percorribili. Ad esempio, per le reti neurali profonde è necessaria una quantità di dati che spesso non è disponibile, e bisogna ricorrere a modelli più semplici.
In tutti i nostri progetti in ambito Data Science la priorità è rappresentata da un'attenta analisi dei requisiti e dei dati a disposizione volta a guidare la scelta della soluzione algoritmica da implementare.
Per determinare quale sia il modello ottimale prendiamo in considerazione ogni possibilità, dai modelli più semplici di regresione lineare e logistica, fino ai più sofisticati metodi di deep learning. Alla fine, il modello scelto è quello che massimizza i KPI decisi con il cliente in simulazioni basate su dati reali.
Alessandro Punzi
Claudio Peroni
Gemma Contini

Certimeter Group crede nei valori, nella passione e nella professionalità delle persone.
 Software
Software
 Security
Security
 Miscellaneous
Miscellaneous