Febbraio, 2020
Big data e Coronavirus - come prevedere la diffusione di un’epidemia
Perché la scienza dei dati è un alleato importante nella lotta contro la prossima pandemia
Giancarlo Ruffo

Il genetista e statistico inglese Ronald Fisher nel suo articolo del 1936 intitolato “The use of multiple measurements in taxonomic problems” non avrebbe mai immaginato che la sua collezione di 150 iris, appartenenti a tre specie diverse (iris setosa, iris virginica e iris versicolor), raccolti nella penisola canadese di Gaspé e misurati uno ad uno in modo tale che fossero raccolti i valori (lunghezza e larghezza) di sepalo e petalo, sarebbe diventata una delle basi di dati più usata - e conseguentemente più odiata - dagli studenti di tutto il mondo per apprendere le basi dell’analisi statistica delle informazioni digitali. Fisher, infatti, raccolse queste informazioni per provare a rendere più preciso il metodo di classificazione di questi fiori, osservando immediatamente un problema di tassonomia che difficilmente si sarebbe potuto risolvere per mezzo di una banale funzione di discriminazione tra valori di variabili tra quelle, fino a quel momento, più comunemente usate. Per risolvere matematicamente questo problema Fisher si sarebbe avvalso della collaborazione di Edgar Anderson che introdusse un metodo di discriminazione lineare che avrebbe posto le basi della cosidetta LDA (Linear Discriminant Analysis, appunto) proprio per poter classificare in modo preciso le tre specie di iris. Questo metodo è oggi considerato uno dei più semplici e nello stesso tempo più potenti strumenti di classificazione statistica, tanto da essere spesso introdotto durante le prime lezioni di molti corsi di “Apprendimento Automatico” (Machine Learning).
Una copia di questa collezione di variabili, a volte indcata come “Fisher’s dataset”, altre volte “Anderson’s dataset”, ma molto più spesso semplicemente “Iris dataset”, è pubblicamente disponibile in molte librerie che oggi tutti i programmatori che amano mettere l’etichetta “data scientist” nel proprio biglietto da visita che usano abitualmente. Ad esempio, se programmate in Python e importate la nota libreria Seaborn usando l’alias sns, potete accedere a questo dataset grazie alla semplice istruzione: iris = sns.load_dataset(‘iris')
Il dataset iris si presenterà così, nella sua forma più grezza:
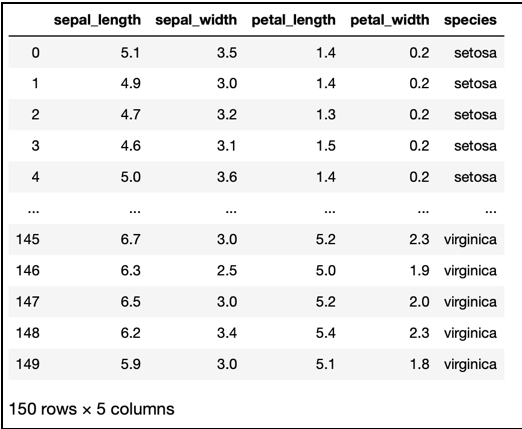
Quello che vediamo sopra è un normale insieme di dati ordinati in forma tabellare che ha una caratteristica fondamentale: ogni “tupla” (o record) corrisponde ad uno dei fiori raccolti da Fisher, caratterizzato da cinque variabili diverse, una delle quali di tipo categorico, che descrive la specie (setosa, versicolor, virginica) e le altre quattro di tipo numerico, che descrivono le misure esatte dei petali e dei sepali dei singoli fiori.
Supponiamo che il signor Fisher si presenti alla nostra porta in un universo parallelo in cui nessuno ha inventato una tecnica simile alla LDA, ma che - nello stesso tempo - gli strumenti di visualizzazione delle informazioni siano paragonabili a quelle che il nostro universo ha saputo maturare. Come possiamo “grattare la schiena” a questi dati cercando di capire le relazioni tra questi valori per poi, eventualmente, cimentarci nell’elaborazione di un modello di classificazione?
Quello che ci troviamo di fronte è un classico problema di analisi visuale di dati multivariati che non può essere risolto con un grafico semplice come un pie chart, o un bar chart, e così via, che risolvono brillantemente la visualizzazione di dati mono o al massimo bi-dimensionali. In questo caso, abbiamo bisogno di qualcosa di maggiormente evoluto: oggi introdurremo diversi tipi di grafici pensati appositamente per dati multivariati, terminando la nostra carrellata con i cosiddetti spider plot: praticamente disegneremo i nostri fiori usando delle tele di ragno, cosa che forse avrebbe fatto piacere ai pionieri di questo ambito che provenivano dal mondo della botanica.
Il nostro iris dataset è molto semplice. Ciononostante, noi non sappiamo ancora nulla dei valori degli attributi che lo caratterizzano. Quali sono i valori massimi, i minimi, le medie? Come si distribuiscono i valori rispetto a questi parametri? Quali sono le soglie che determinano i percentili principali? Domande di questo tipo sono fondamentali per capire come impostare le basi dei grafici, come disegnare le assi cartesiane, le scale da usare, in quali aree aspettarci densità di dati rilevanti, etc. Fortunatamente, quasi tutti gli ambienti di analisi dei dati forniscono dei metodi per raggruppare le informazioni corrispondenti alla cosiddetta statistica descrittiva in una tabella come quella che trovate in basso:
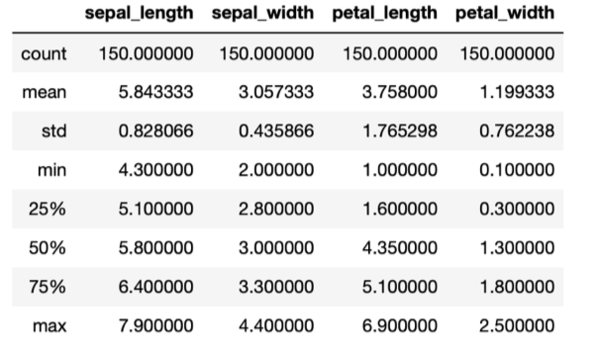
Esistono diversi metodi per iniziare a visualizzare queste informazioni “aggregate” e per aiutare il nostro occhio a capire quali variabili esplorare per prime, per cominciare a dare un senso a questi numeri, consentendo loro di raccontare qualche tipo di storia. Il cosiddetto “Box and Whisker Plot” è uno degli strumenti grafici più comuni quando si tratta di dare una forma alla statistica descrittiva di un dataset:
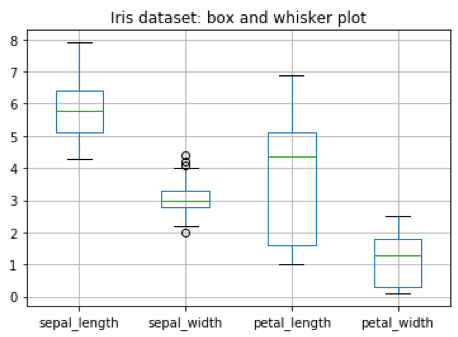
I rettangoli consentono una rappresentazione molto efficace dei cosidetti ‘scarti interquartili” (https://it.wikipedia.org/wiki/Scarto_interquartile) che consentono di evidenziare l’ampiezza della fascia dei valori relativi alle variabili di tipo numerico. Certamente una rappresentazione aggregata di questo tipo non ci aiuta ad individuare i valori e le variabili che meglio caratterizzano una specie di iris rispetto alle altre. Però riusciamo ad identificare visivamente molte cose. Una di queste è che la “lunghezza del petalo” è la variabile che presenta l’ampiezza della fascia dei valori maggiore. Vale la pena concentrarci su questa variabile per tentare una prima discriminazione tra le specie. Usiamo nuovamente il “box and whisker plot”; questa volta però mostreremo le distribuzioni per singola specie di iris relativamente alla sola variabile “petal_length”. Alla sua destra proponiamo una visualizzazione alternativa, dove usiamo uno scatterplot modificato in modo tale che il problema della sovrapposizione dei punti, ognuno rappresentante un fiore diverso, viene smussato grazie ad un uso combinato di tecniche di jittering e di trasparenze per fare risaltare le aree con densità maggiore.
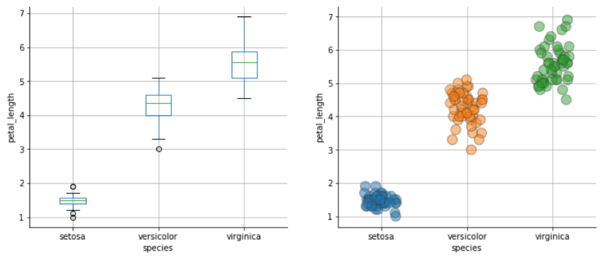
La potenzialità della visualizzazione dati avanzata si percepisce già da questo semplice esempio: senza che ci siamo avventurati nei dettagli matematici di una LDA, ne abbiamo individuato una componente: è possibile discriminare una specie rispetto alle altre in modo netto. Infatti, se molti iris del tipo ‘versicolor’ e del tipo ‘virginica’ presentano una certa sovrapposizione tra i valori della lunghezza dei loro petali, i campioni della specie ‘setosa’ presentano invece dei petali nettamente inferiori rispetto agli altri.
Nella sezione precedente abbiamo guardato i dati grazie ad una sorta di “volo d’uccello”: la statistica descrittiva ed il box and whisker plot ci hanno permesso di farci un’idea di insieme dei valori che caratterizzano il nostro dataset. Quindi, siamo riusciti ad andare “in picchiata” e ad approfondire il comportamento dei valori di una variabile numerica continua (“petal_lenght”) in funzione di una variabile con valori discreti (“species”). Possiamo legittimamente chiederci se abbiamo messo a confronto le coppie di variabili più interessanti. Questa riflessione ci conduce inevitabilmente a trovare un modo per mettere a confronto tutte le variabili con tutte le altre ed uno schema di visualizzazione di questo tipo è noto come Small Multiple, introdotto nei termini seguenti da Edward Tufte nel suo libro Envisioning Information (1990):
“Al centro del ragionamento quantitativo c'è una sola domanda: rispetto a cosa? Piccoli grafici multipli [small multiples], multivariati e ricchi di dati, rispondono direttamente [a tale domanda] applicando confronti visivi di cambiamenti tra valori, differenze tra oggetti, intervalli di riferimento. Per una vasta gamma di problemi nella presentazione dei dati, gli ‘small multiple’ sono la soluzione migliore.”
Ad esempio, possiamo avere una griglia di plot che rappresentano funzioni di densità, con le stesse scale negli assi per facilitare i confronti, dedicando ogni riga ad una diversa specie di iris, e ogni colonna ad una delle variabili numeriche continue che abbiamo nel nostro dataset:
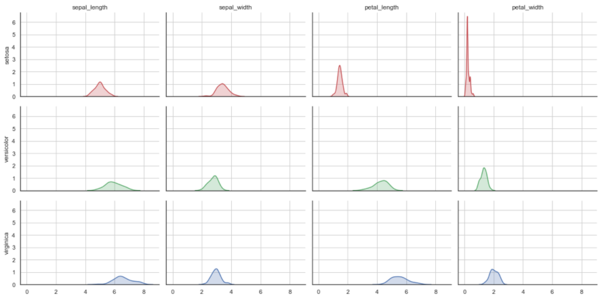
I confronti sono possibili facendo scorrere il nostro sguardo in senso orizzontale o in senso verticale, spostando la nostra attenzione da una variabile numerica all’altra e/o da una specie all’altra.
In alternativa, possiamo usare una scatterplot matrix: una griglia in cui ogni cella riporta lo scatterplot delle variabili x e y determinate dall’incrocio tra la dimensione orizzontale e quella verticale e dove la diagonale può essere usata per una rappresentazione monodimensionale classica (avendo a che fare con un incrocio di una variabile con se stessa, possiamo sfruttare i classici bar chart, histogtram, line plot, area chart, etc.).
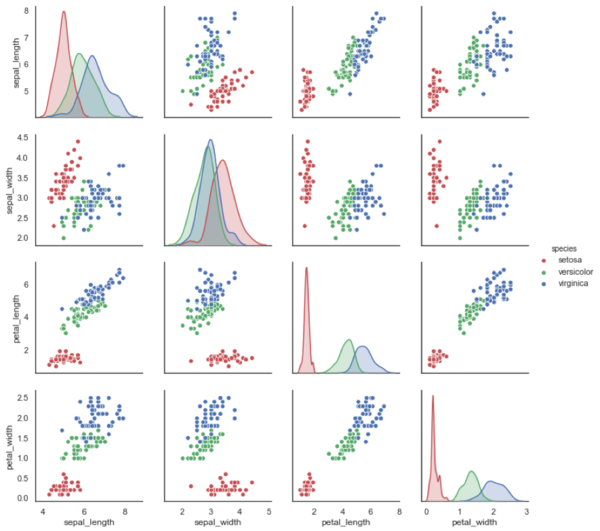
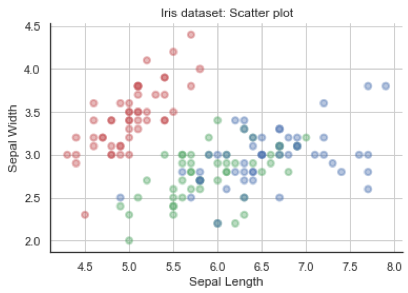
Nulla ci vieta che dopo una tale overview, si possa decidere di fare uno zoom su uno di questi plot in particolare, ad esempio lo scatter plot mostrato nella cella (2,1) che mette in relazione la lunghezza del sepalo con la larghezza del petalo.
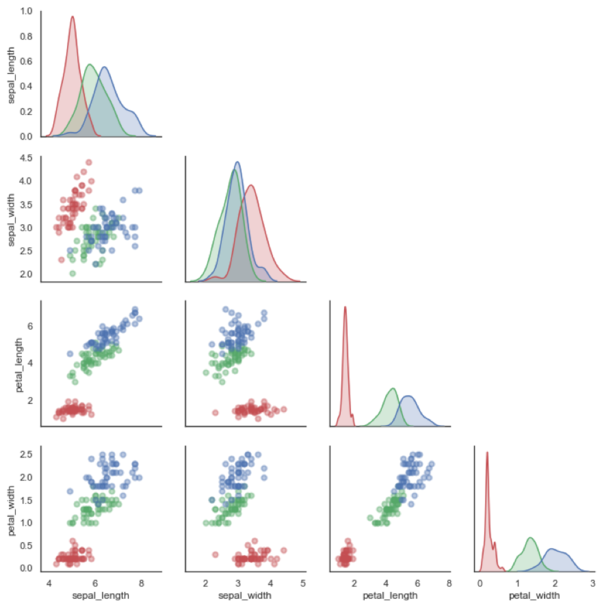
Infine, si noti che la simmetria di tale rappresentazione, potrebbe indurci a “risparmiare spazio” e usare soltanto la diagonale inferiore della matrice:
Per quanto sia possibile approfondire per ogni singola visualizzazione proposta le riflessioni in modo da evidenziare pregi e difetti, oltre che adeguatezza per tipologia di dataset, concentriamoci su un diagramma tra i più efficaci quando si tratta di dover mettere a confronto valori diversi. Il cosidetto spider plot (o anche detto radar plot, web chart, polar chart, star plot) è basato su un’idea semplice quanto vincente. Ogni tupla corrisponde ad una linea che viene disegnata lungo una serie di assi disposti in senso radiale a partire da un centro comune. Ogni asse corrisponde ad una variabile numerica diversa ed il punto dove la linea rappresentante la tupla interseca l’asse rappresenta il valore che quel particolare elemento assume per quella variabile. Ad esempio, confrontando i calori di tre dei 150 fiori del nostro dataset, uno per ogni specie diversa, avremmo:
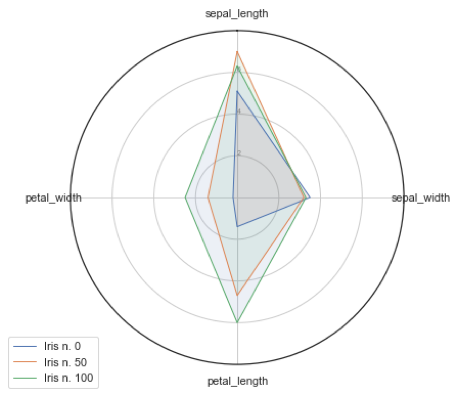
Una delle caratteristiche più interessanti degli spider plot è che esso consente di dare effettiva forma (un poligono) ad un singolo dato, come se fosse l’impronta digitale di quella particolare tupla. Potremmo difatti “divertirci” disegnando la forma di ogni singolo fiore, ma una forma che parte dai numeri e che, grazie all’eliminazione degli assi e delle etichette che guidano l’occhio, restituisce una qualità astratta al dato:
Qual è, quindi, la migliore rappresentazione visiva di un dataset multivariato? Come crediamo sia facile immaginare a questo punto, non esiste una risposta valida per tutte le stagioni: dipende dalla domanda che ci stiamo ponendo, dall’utente che dovrebbe fruire della realizzazione finale e, non ultimo, dal dataset stesso: basti pensare ai casi in cui le variabili non siano semplicemente numeri, ma rappresentino coordinate geografiche, momenti temporali, informazioni non strutturate, etc.
È fondamentale pertanto che il dato venga rispettato e non torturato affinché racconti una storia sbagliata. Bisogna spesso conoscere le caratteristiche matematiche e geometriche delle funzioni che si usano per trasformare le informazioni; si deve accettare l’idea che la data visualization è scienza, ma anche artigianato. In definitiva, se vi trovate di fronte ad un’infografica che vi piace e che vi sta davvero facendo capire il dato che c’è sotto, potete stare sicuri di una cosa: chi l’ha realizzata ha speso tantissimo tempo per raggiungere quella versione ed ha applicato tecniche diverse che provengono dalla matematica, dalla psicologica cognitiva, dalla grafica computerizzata, dalla conoscenza approfondita di almeno un linguaggio di programmazione avanzato (come Python, R, Processing, Javascript e, in alcuni casi, perfino C e C++).
Nota: tutto il codice usato per ottenere i grafici presenti in questo articolo è disponibile al repository Github dell’autore https://github.com/giaruffo/dataviz
Claudio Peroni
Gemma Contini
Roberto Gazzola

Certimeter Group crede nei valori, nella passione e nella professionalità delle persone.
 Software
Software
 Security
Security
 Miscellaneous
Miscellaneous